
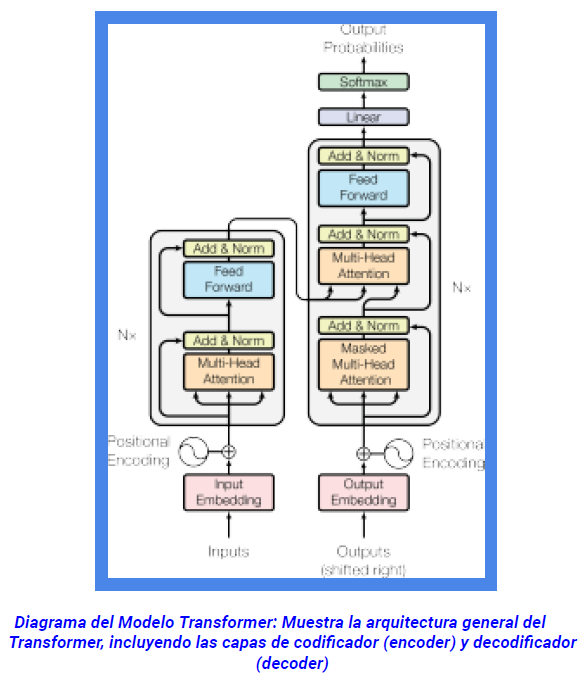
Concepto
“Attention Is All You Need”. Es la base a partir del cual se desarrollan los transformers y la mayoría y más exitosos modelos de IA que se utilizan actualmente en la IA generativa y no generativa.
Otros aspectos
Comencemos explicando cómo se realizaba el embedding previo al uso de transformers. Primeramente las palabras debían ser codificadas en método binario one-hot encodding. Una red neuronal (con aprendizaje no supervisado) se encargaba de reducir su dimensionalidad de tal forma que las palabras se encontraran organizadas y representadas en cluster cercanos según su parecido → representación eficiente de las palabras. La idea aquí es entrenar la matriz de peso de la capa oculta para encontrar representaciones
eficientes para nuestras palabras. Esta matriz de ponderación suele denominarse matriz de incrustación. Esta representación además permite la manipulación aritmética de las palabras.