
Concepto
CNN
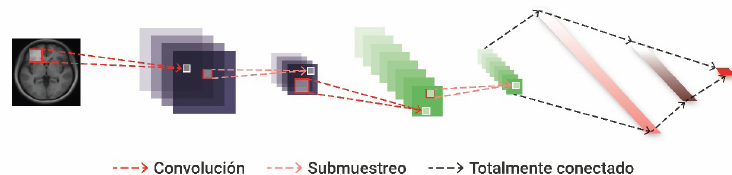
Transformar las imágenes en vectores de 1D inevitablemente destruye esta información. Las redes neuronales convolucionales son un tipo particular de redes neuronales que intercala neuronas convolucionales con neuronas de reducción de muestreo (pooling en inglés), seguidas posteriormente de capas totalmente conectadas al igual que en un red neuronal estándar.
- Pretenden encontrar “features”=características de las imágenes de entrada.
- Los Kernels=filtros (Kij) son los pesos de estas redes à Transforman capa de entrada K a I
- Los Kernels van produciendo reducción de la dimensionalidad de la imagen pero en contraste con una simple reducción de tamaño, puede preservar la información de manera más óptima.
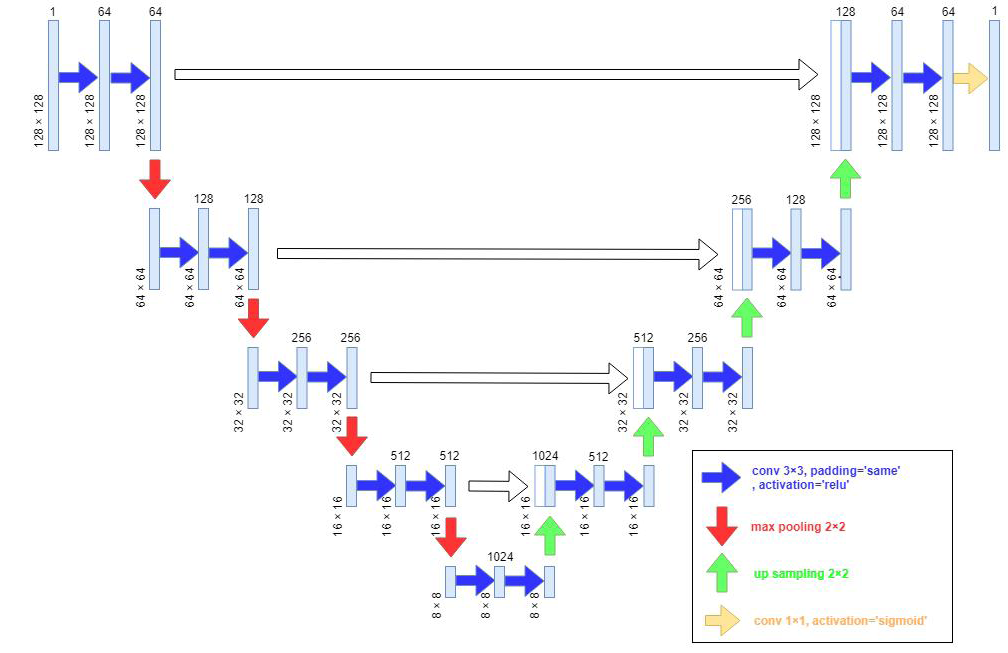
- Usos en imagen médica: segmentación de tumores u órganos. La más famosa de ellas desarrollada en 2015 es la red U-NET (Ejemplo: The Multimodal Brain Tumor Image Segmentation Benchmark (BRATS) (nih.gov)). ). Posteriormente se han adicionado transformers a esta red con buenos resultadosà TransUNet.
La U-Net: Estructura en forma de U; consta de codificación (contracción) y una parte de decodificación (expansión). ¿Cómo actúa?: Diseñada para reducir la dimensionalidad de la imagen (contracciónà red convolucional invertida que vuelve a reemplazar la imagen (esta vez al alza) para producir una salida del mismo tamaño que la entrada. ¿Con qué fin? La contracción permite reducir la dimensionalidad y permitir que la imagen se centre en características de alto nivel; esto lo conseguir a medida que se implementan más filtros para poder más características diferentes. En el proceso de la decodificación se obtiene la segmentación.
Redes generativas antagónicas
Las Redes Generativas Antagónicas, también conocidas como GANs: Sistema híbrido de aprendizaje no supervisado y aprendizaje reforzado. Fueron desarrolladas en 2014.
Componentes: 2 redes neuronales que compiten mutuamente en una especie de juego de suma cero.
¿Cómo actúa?: Dado un conjunto de entrenamiento la red generativa (generador) genera candidatos mientras que la red discriminativa (discriminador) los evalúa discriminando los generados del grupo de la verdadera distribución de datos.
Objetivo: Aumentar la tasa de error del discriminador.
Usos: Generación de imágenes (útil en entornos de escasez de datos) y descubrir la estructura subyacente de los datos proporcionados. Eliminación de artefactos de imágenes (en la actualidad, los métodos de reconstrucción basados en GAN carecen de análisis estadísticos a gran escala realizados por un observador humano)(uso del marco de pix2pix, que se ha utilizado para el denoising (reducción de ruido) de las imágenes de CT) Segmentación: Las GANs proponen una alternativa interesante y se cree que la competición entre ambas redes puede ayudar a refinar aún más los métodos de segmentación por machine learning. En este caso, el discriminador puede considerarse un regulador de forma.
Este efecto de regularización es más prominente cuando el objeto de interés tiene una
forma compacta; por ejemplo, para la máscara de pulmón y corazón, pero es menos útil para los objetos deformables, como los vasos y los catéteres.
Otros aspectos
Máquinas de vectores de soporte
Componentes: Genera hiperplano de clases de forma iterativa buscando el conjunto de parámetros óptimos que minimizan el error asociado e intentando crear una separación geométrica perfecta ta entre clases.
Utilidad: Clasificación lineal y no lineal así como problemas de regresión o detección de valores atípicos, de conjuntos de datos complejos de mediano o pequeño tamaño.
¿Vector de soporte?: Aquellos puntos de los datos que definen la posición y el margen del hiperplano óptimo. Se denominan de “soporte” porque indican las coordenadas representativas de las clases. Mover otros puntos no tiene efecto.
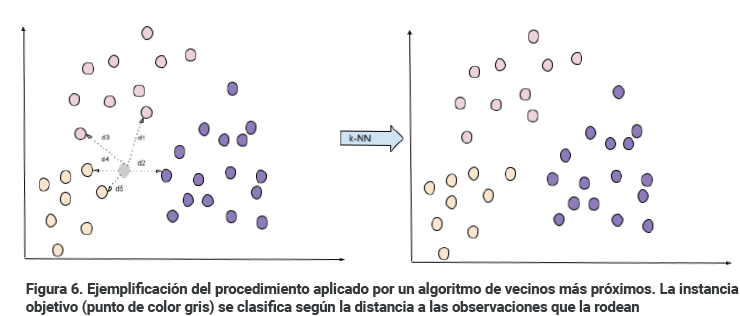
Vecinos más cercanos=k-NN (k-Nearest Neighbors)
Componentes: k-NN pertenecen a la denominada categoría de análisis no paramétricos, esto significa que no realizan ninguna suposición a priori sobre la distribución subyacente a los datos. Al contrario que en las técnicas anteriores donde asumíamos una relación lineal o logarítmica (modelo) entre los datos y las variables objetivo y tratábamos de encontrar los coeficientes o pesos que producían un mejor ajuste, un algoritmo k-NN memoriza las observaciones o instancias de entrenamiento para usarlas como base de conocimiento del mundo real en la fase de predicción. Las soluciones obtenidas aplicando métodos k-NN no son generalizadoras, sino que simplemente recuerdan los valores adecuados para el conjunto de datos con el que ha aprendido. Por este motivo los algoritmos k-NN son una buena elección para trabajar en problemas de clasificación sobre los que tengamos poco o ningún conocimiento previo acerca de la distribución de los datos.
Utilidad: Problemas de regresión como en tareas de clasificación.
¿Cómo actúa clasificando?: Selecciona la clase donde un dato se asocia a un cierto grupo si tiene k vecinos más cerca de aquel que de otro grupo.
Árboles de decisión:
Utilidad: Problemas de clasificación como de regresión
¿Cómo actúa clasificando?: Pretende ir encontrando las características que mejor separan a un conjunto de datos utilizando en cada nodo la característica que produce la separación óptima entre subgrupos de datos
La medida del desempeño en esta tarea, o criterio de minimización, nos la proporcionarán métricas dedicadas como el índice de Gini (Gini o impureza es una medida de la frecuencia con la que un elemento del conjunto de datos resulta erróneamente clasificado en un etiquetado aleatorio) o el valor de entropía.
Poseen problemas de sobreajuste con bastante facilidad.